

如何优化“两层for循环”提高代码性能与可读性
 发布时间:2025-03-13 01:33
发布时间:2025-03-13 01:33 发布者:好资源AI
发布者:好资源AI 浏览次数:
浏览次数:在编程中,循环是最常见的控制结构之一,尤其是for循环。许多算法和数据结构的实现都依赖于循环来遍历数组或集合,尤其是在需要进行嵌套操作时。常见的“两层for循环”是指两个嵌套的for循环,这种结构在许多任务中是不可避免的。无论是在查找最短路径,排序算法,还是矩阵运算中,两层for循环都有着广泛的应用。尽管两层for循环十分常见,它们的性能开销却往往成为程序执行效率的瓶颈。如何优化两层for循环,提升代码性能,降低时间复杂度,一直是程序员面临的难题。

一、理解两层for循环的性能问题
我们需要清楚地认识到两层for循环的性能瓶颈所在。两层for循环通常会导致算法的时间复杂度为O(n²),其中n表示数据的规模。例如,如果我们需要遍历一个二维数组(n×n),则通过两层for循环遍历所有元素时,时间复杂度是O(n²)。随着数据规模的增大,O(n²)的算法运行时间会急剧增加,这对于大数据处理和高效编程来说无疑是个巨大挑战。
以一个简单的例子来说明,假设我们要通过两层for循环找出一个矩阵中的所有大于某个阈值的元素:
foriinrange(n):
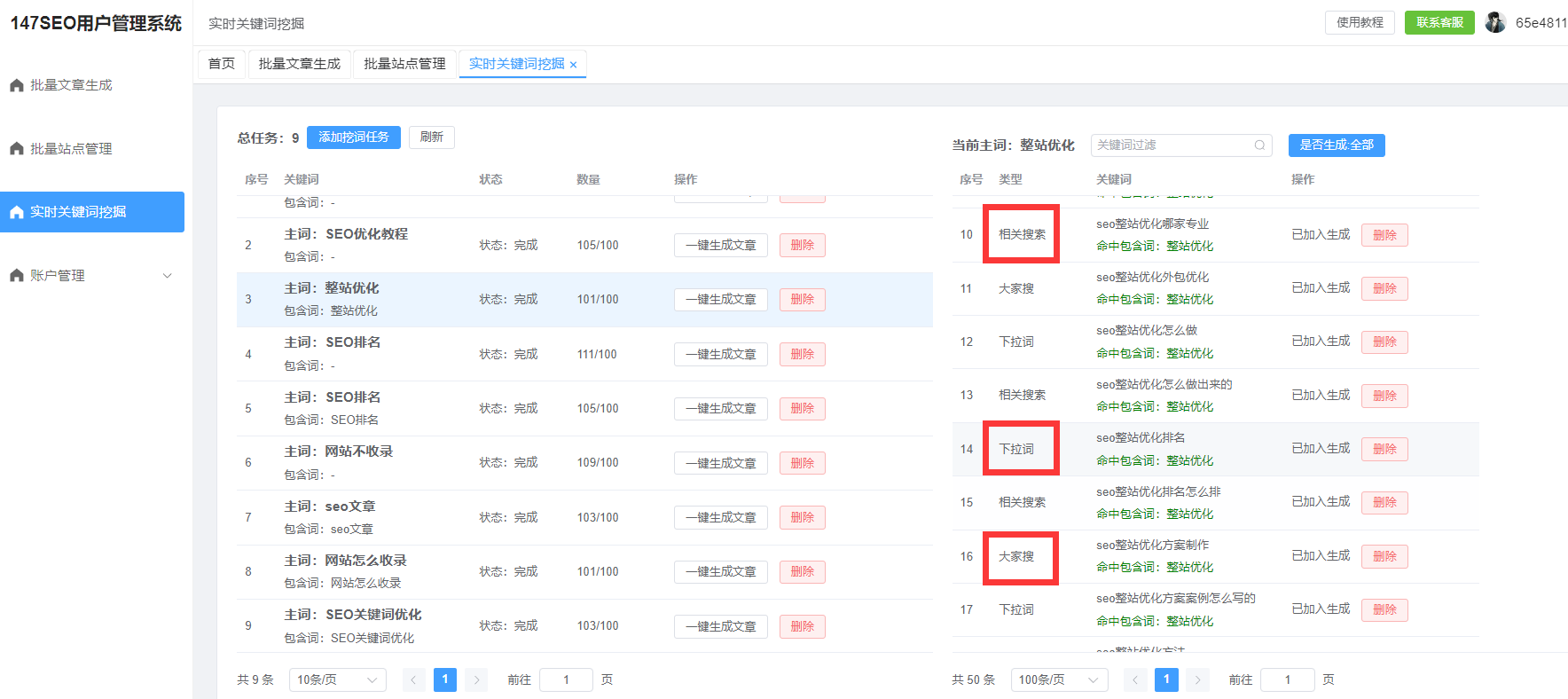
forjinrange(n):
ifmatrix[i][j]>threshold:
print(matrix[i][j])
在这个示例中,我们使用了两层for循环遍历n×n的矩阵,若矩阵的规模较大时,时间复杂度将变得非常高,导致程序运行缓慢。尤其是在需要处理上百万级数据时,O(n²)的算法会迅速变得不可接受。
二、优化“两层for循环”的方向
在理解了两层for循环的性能瓶颈后,我们就可以开始着手优化了。优化的目标是减少不必要的重复计算和简化程序的结构,下面是几个常见的优化方向。
1.减少不必要的计算
很多时候,我们在两层for循环中会进行一些重复的计算,尤其是涉及到复杂的判断和计算时。通过缓存中间结果、避免不必要的重复运算,可以大大提升程序的效率。例如,避免在循环中进行多次相同的数据访问或计算,可以将其提取到循环外部,减少计算量。

假设我们有一个算法需要在每次循环中进行某些计算,比如矩阵乘法。在这种情况下,优化的关键就是避免每次循环都重新计算相同的部分。
#原始代码:
foriinrange(n):
forjinrange(n):
result[i][j]=matrix[i][j]*constant
#优化后的代码:
multiplier=constant#提前计算常量
foriinrange(n):
forjinrange(n):
result[i][j]=matrix[i][j]*multiplier
通过将常量提前计算出来,避免了在每次循环中都进行重复的乘法操作,从而提升了性能。
2.提升数据存取效率
有时,性能瓶颈并不完全来源于算法本身,而是由于数据存取的效率低下。在二维数组中,数据的访问顺序可能并不总是最优的,导致缓存失效或内存访问的不高效。在进行两层for循环时,数据访问顺序的优化也是一个提升性能的关键。
例如,考虑一个二维数组的行优先访问和列优先访问。由于现代计算机的内存是按行存储的,行优先访问会比列优先访问更具性能优势。优化数据存取顺序能够显著提高循环的执行效率。
#行优先访问
foriinrange(n):
forjinrange(n):
process(matrix[i][j])
#列优先访问
forjinrange(n):
foriinrange(n):
process(matrix[i][j])
如果矩阵是按行优先存储的,行优先访问会更有效,因为它能够更好地利用缓存。
3.使用数学公式和数据结构
在某些情况下,可以通过数学公式或更高效的数据结构来避免两层for循环。例如,当我们需要在数组中寻找某些特定值时,哈希表就比传统的双重循环要高效得多。通过数学公式优化,可以减少不必要的计算,或者通过替换数据结构来避免嵌套循环的使用。
例如,假设我们要查找两个数组中所有的配对元素,可以使用哈希表来进行优化:
#原始两层循环方法
foriinrange(len(arr1)):
forjinrange(len(arr2)):
ifarr1[i]==arr2[j]:
print(arr1[i])
#使用哈希表优化
arr2set=set(arr2)
foriinrange(len(arr1)):
ifarr1[i]inarr2set:
print(arr1[i])
通过哈希表查找,我们将时间复杂度从O(n²)降到了O(n),大大提高了算法的效率。
4.早期退出与剪枝
有时候,两层for循环中的某些条件可以提前判断并终止当前循环,这种方法叫做“提前退出”或“剪枝”。通过减少不必要的迭代,可以有效地提高代码效率,尤其是在嵌套循环中。
例如,当我们在进行矩阵搜索时,发现某个条件不满足时,可以立刻跳出循环,而不是进行下去。这样可以避免无用的计算,节省时间。
#未优化的循环
foriinrange(n):
forjinrange(n):
ifmatrix[i][j]==target:
print("Found!")
break
#优化后的循环
foriinrange(n):
forjinrange(n):
ifmatrix[i][j]==target:
print("Found!")
return
通过提前返回或退出循环,我们避免了无意义的搜索,从而提高了算法的执行效率。
优化“两层for循环”的技巧不仅能够提升代码性能,还能够使代码更加简洁和可维护。通过合理应用上述方法,开发人员可以更好地应对各种算法中的挑战,尤其是在处理大数据时。通过减少不必要的计算、优化数据存取顺序、利用更高效的数据结构等手段,可以显著减少程序的执行时间,提高代码的效率。
三、其他优化技巧
除了前面提到的优化策略,还有一些其他的方法可以进一步提升两层for循环的性能。
1.避免不必要的内存分配
在某些情况下,内存分配本身也可能成为程序瓶颈。尤其是在循环内部进行大量内存分配时,频繁的内存分配和回收会增加系统负担,影响性能。通过避免在循环内进行不必要的内存分配,可以有效提升程序的性能。
#不良示例:每次循环都分配内存
foriinrange(n):
result=[]
forjinrange(n):
result.append(matrix[i][j])
#优化示例:循环外部提前分配内存
result=[[]forinrange(n)]#预先分配内存
foriinrange(n):
forjinrange(n):
result[i].append(matrix[i][j])
通过预先分配内存,可以避免每次循环中重复的内存分配,提升性能。
2.并行化处理
对于一些计算密集型任务,尤其是涉及大量数据的场景,可以考虑将两层for循环的任务并行化处理。现代处理器通常具有多个核心,可以利用并行计算来提升效率。
例如,使用Python中的concurrent.futures模块,可以将循环任务分配到多个线程或进程中执行,从而缩短运行时间。
fromconcurrent.futuresimportThreadPoolExecutor
defprocesselement(i,j):
#处理矩阵元素的函数
returnmatrix[i][j]*constant
withThreadPoolExecutor()asexecutor:
futures=[executor.submit(processelement,i,j)foriinrange(n)forjinrange(n)]
results=[future.result()forfutureinfutures]
通过并行化处理,能够更充分地利用多核CPU的计算能力,加速循环操作。
3.算法改进
在某些情况下,优化两层for循环的最佳方法是完全改变算法本身。虽然两层for循环在很多问题中是不可避免的,但有时可以通过改变算法来避免不必要的循环。例如,在处理图算法时,Dijkstra算法和A*算法就比传统的暴力搜索算法更有效。通过选择合适的算法,可以避免使用两层for循环,从而提升性能。
通过这些优化技巧,不仅可以提升“两层for循环”的执行效率,还可以让程序在面对大规模数据时更加高效和稳定。希望本文能够帮助你深入理解两层for循环的优化方法,让你在编程的道路上更加游刃有余,写出高效且可维护的代码。







